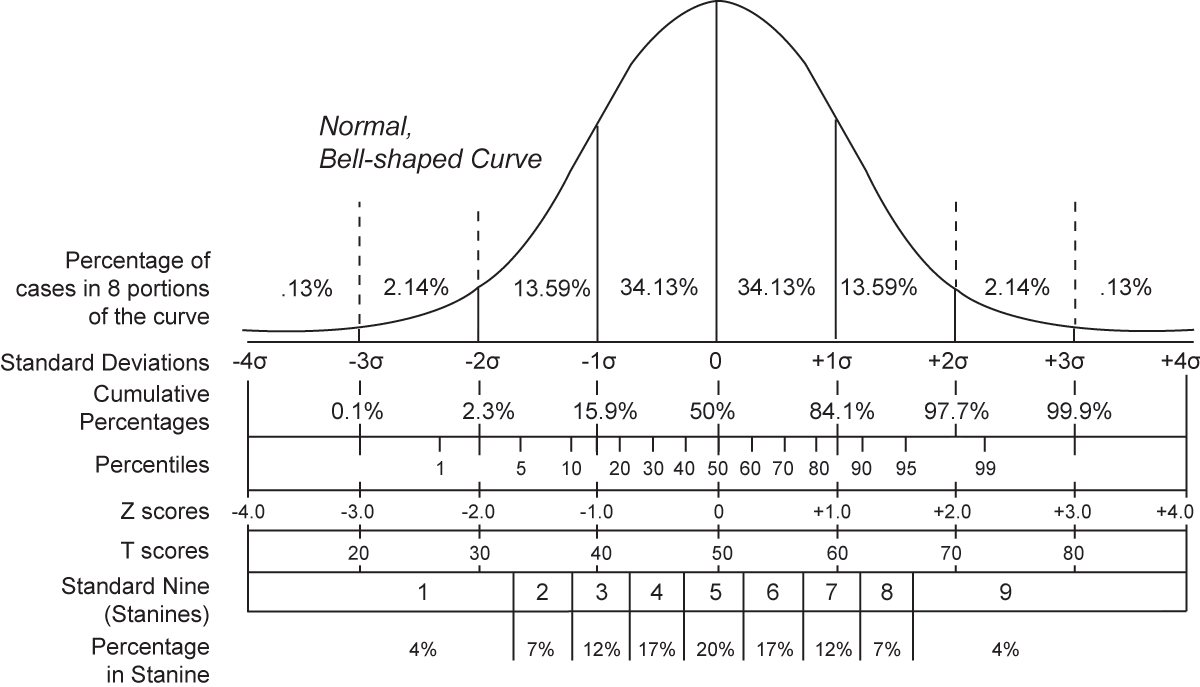
Empirical Rule of Statistics, applies to all standard/normal/symmetrical distributions:
If you travel out to 1 standard deviation, you collect 68% of the observations.
If you travel out to 2 standard deviation, you collect 95% of the observations.
If you travel out to 3 standard deviation, you collect 99.7% of the observations.
Anything beyond 3 standard deviations is unexpected, but we will continue to use the 1.5IQR method to declare outliers.
If the z-score is exactly average, the value is 0. This is the 50th percentile.
If you are unclear on any of this please watch this video
3.5) Applying the Empirical Rule
6. Normal Distribution, never assume normal. Must be standard!
9. No cannot use it. However if we could, μ =100, σ = 10, drawing it. we determine that values of 80 and 120 correspond to 2 standard deviations, which would catch 95% of the data.
Example: Birth weights
μ = 3300 grams, σ = 570 grams
Drawing a Normal Distribution we have a 3300 at the center.
Moving to the right: +1 is 3870, +2 is is 4440, +3 is 5010.
Moving to the left: -1 is 2730, -2 is 2160, -3 is 1590.
Criteria for a "low birth weight" is a weight of less than 2500 grams. Where does this fall on our distribution?
(2500-3300)/570 = 1.4 standard deviations BELOW average.
What is the percentage of observations within one standard deviation? 68%
What is the percentage of observations below one standard deviation? 84% (50% + 34%, why 50%? because we know fifty percent of the data lies on either side of the mean. Why 34%? because we know 68% of the data falls within 1 standard deviation, so if one half of the 68% is already accounted for in the previously mentioned 50% we are left with the other half and half of 68% is 34%.)
How many standard deviations away from the mean is a birth weight of 3600 grams? (3600-3300)/570 = +0.53
How many standard deviations away from the mean is a birth weight of 4536 grams? (4536-3300)/570 = +2.17
How many standard deviations away from the mean is a birth weight of 5443 grams? (5443-3300)/570 = +3.76
Suppose we are given a z-score and want to determine the original observation.
Continuing with our birth weight distribution, we have a z-score of: -3.76 and we want to know the weight that corresponds with this extremely low z-score.
How do we set it up? We just use some algebra on the z-score formula we already know:


-3.76 = (x - 3300)/570
-3.76(570) = x -3300 (multiplying both sides by the standard deviation)
-2143.2 = x - 3300
1156.8=x (adding the mean to both sides)


























































{kind=link}
{kind=link}
{kind=link}